
Por que falar de RBM agora
Em operações industriais, pouca coisa dói mais do que parar a linha por falha de um ativo crítico. A gestão de ativos orientada a risco (RBM) organiza decisões de manutenção olhando para probabilidade de falha (POF) e consequência (COF), priorizando o que realmente ameaça segurança, produção e caixa. O tema ganhou tração porque o downtime não planejado segue custando caro — grandes empresas perdem somas bilionárias por paradas e estão acelerando técnicas preditivas com IA e robótica para evitar falhas.
A RBM conversa diretamente com a ISO 55000:2024, que orienta sistemas de gestão de ativos ao longo do ciclo de vida, equilibrando desempenho, custo e risco.
O que é RBM (na prática)
RBM é um método de priorização: você mede POF e COF por ativo/sistema, cruza com criticidade do processo e direciona recursos para onde o risco é maior. Em vez de “distribuir” manutenção por calendário, você foca nos pontos que param a linha — e reduz esforço desnecessário nos de baixo risco. WorkTrek
O parentesco com RBI (API 580)
Embora RBM (manutenção) e RBI (inspeção baseada em risco) não sejam a mesma coisa, compartilham o raciocínio de quantificar POF e COF. A API RP 580 (4ª ed., 2023; Addendum 2025) consolidou elementos obrigatórios de avaliação de risco e governança, útil como referência metodológica para programas industriais.
Framework essencial de RBM com IA
1) Defina escopo e criticidade
Mapeie linhas, gargalos e ativos cuja falha derruba OEE, compromete segurança ou viola conformidades. Use matriz de criticidade para visibilidade inicial.
2) Estruture as bases de risco (POF×COF)
-
POF: histórico de falhas, condições de operação, idade/uso, sinais de degradação (vibração, temperatura, corrente, acústica).
-
COF: impacto em segurança, meio ambiente, produção e custo (inclua penalidades contratuais).
-
Risco = POF × COF → crie tiers de prioridade e janelas de intervenção.
3) Desdobre em modos de falha (FMEA/FMECA)
Aplique IEC 60812:2018 para identificar failure modes, efeitos e criticidade; isso alimenta tanto a modelagem de risco quanto a IA (features).
4) Conecte dados e IA
-
Sensores IoT e dados de CLP/SCADA/MES.
-
Pipelines de qualidade de dados (limpeza, contextualização e padronização).
-
Modelos de anomaly detection e prognóstico (vida remanescente, tendência).
-
Alertas priorizados por risco (não apenas por desvio). Dados “IA-prontos” são o maior gargalo; sem governança e padronização, a IA entrega pouco.
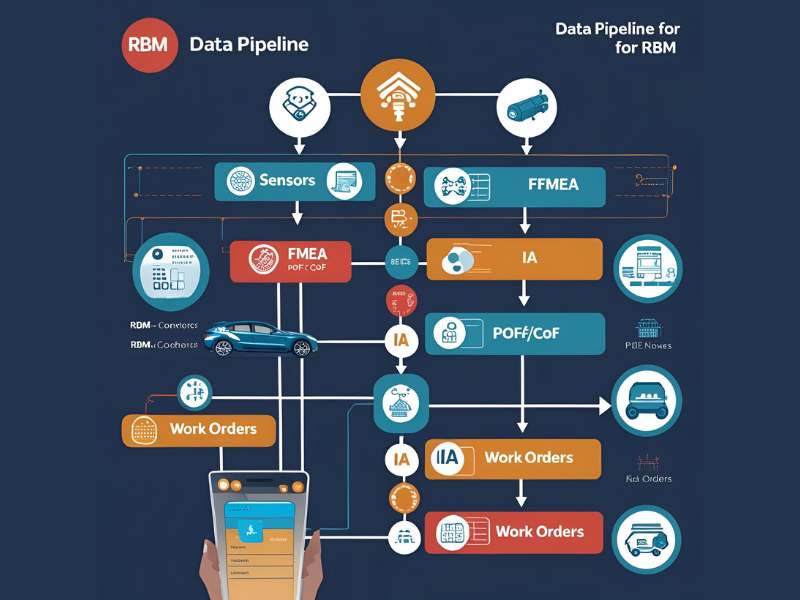
5) Orquestração no dia a dia
Integrar RBM ao CMMS/ERP: quando a IA sinaliza anomalia em um ativo Tier 1, cria-se a ordem de serviço com SLA, peças e janela de parada negociada. Em Tier 3, monitora e reavalia.
6) Feedback loop
Toda intervenção alimenta a base de risco: o modelo melhora, thresholds refinam e o planejamento de inspeções (quando aplicável) se ajusta.
Métricas que importam
-
Taxa de risco mitigado (% de risco removido por mês).
-
Horas de downtime evitadas (por ativo e por linha).
-
Backlog de alto risco (nº de ordens Tier 1 pendentes).
-
MTBF/MTTR por classe de criticidade.
-
Payback (economia por falhas evitadas × investimento).
Mercado e tendências mostram crescimento contínuo de soluções de manutenção preditiva e risco — sinal de maturidade e ROI percebido.
Checklist para implementar sem tropeços
Governança & método
-
Patrocínio da liderança e política de risco clara (limiares por segurança, meio ambiente e produção).
-
Procedimentos compatíveis com ISO 55000 e playbooks por classe de ativo. ISO
Dados & modelos
-
Catálogo de dados OT/IT; taxonomia única de ativos.
-
Qualidade de dados (missing, drift, sincronismo) monitorada.
-
Modelos explicáveis (faça o técnico entender “o porquê” do alerta).
-
Simulação de cenários (e se uma bomba A falhar no turno C?).
Processo & pessoas
-
RBM integrado à rotina de manutenção e produção (reuniões de risco semanais).
-
Capacitação em FMEA/FMECA e uso dos dashboards.
-
Indicadores de segurança e meio ambiente no mesmo painel do OEE.
Tecnologia
-
Sensores plug-and-play (vibração, ultrassom, termografia, energia).
-
Edge para eventos em tempo real e cloud para histórico/modelos.
-
API aberta para CMMS/MES/ERP.

Exemplo rápido (linha de envase)
-
Criticidade: enchedoras e sopradoras como Tier 1 (param a linha).
-
FMEA: rolamentos e eixo principal com modos de falha dominantes; COF alto por perdas de produção e risco de dano secundário.
-
IA: anomalia de vibração + aumento de corrente → risco sobe acima do limiar → ordem de serviço planejada na troca de turno.
-
Resultado: janela de 40 minutos evita quebra, reduz MTTR e não afeta o throughput do dia.
Erros comuns (e como evitar)
-
Confundir calendário com risco: RBM não é PM “com planilha bonita”; é priorização por POF×COF.
-
Ignorar governança: sem papéis, aprovações e trilhas de auditoria (inspiradas em padrões como API 580 para processos formais), o sistema perde credibilidade.
-
Dados crus demais: sem tratar e contextualizar dados, a IA vira alarme falso.
Conclusão e próximos passos
Gestão de ativos orientada a risco com IA muda a conversa: menos incêndio, mais decisão. Comece pelo mapa de criticidade, aplique FMEA/FMECA, conecte dados “IA-prontos” e integre tudo ao CMMS. Em poucas semanas, você verá o backlog reorganizado pelo que para a linha — e caixa voltando para o lado certo.
CTA: Quer um diagnóstico rápido de RBM com IA nos seus ativos críticos? Fale com a Activa e descubra onde está o maior ganho potencial.


